In general, we use databases to implement functions such as storing and retrieving data. A relational database system based on the C/S structure like MySQL, while representing the current mainstream of database applications, does not meet the needs of all applications. Many applications only use the basic features of these database products. Sometimes we need only a simple disk file-based database system, so you do not have to install a large database server to simplify the design of database applications. In some special applications, such as embedded systems, due to the limited hardware and software resources of the system, these database products are obviously bloated or even unrealizable. In these cases, the advantages of the embedded database are particularly evident.
The embedded database is usually integrated with the operating system and specific applications. There is no need to run the database engine independently. The program directly calls the corresponding API to access the data. To put it more succinctly, an embedded database is a data file that has basic database features. The difference between an embedded database and other database products is that the former is program-driven and the latter is engine-responsive. A very important feature of embedded databases is that they are very small, and the compiled product is only a few tens of kilobytes. It is very competitive on some mobile devices.
From the current development trend of embedded applications, the implementation of embedded database must fully reflect the system's customizability, that is, the technical route chosen by the system must be oriented to specific industry applications. Therefore, the study of open source embedded databases has special significance.
2 Berkeley DBBerkeley DB is a lightweight embedded database developed by sleepycat software. It is not only suitable for embedded systems, but also can be directly connected to applications and run in the same address space as applications. The traditional database usually works as a stand-alone server. Berkeley DB is a software development library. The developer embeds it into the application. The application itself is a server. It only uses embedded database development to implement the customized database logic and avoids it. Because of the overhead of communication with application server processes, Berkeley DB has high operating efficiency and is suitable for resource-constrained embedded systems.
In general, the Berkeley DB database system can be roughly divided into five subsystems, as shown in Figure 1.
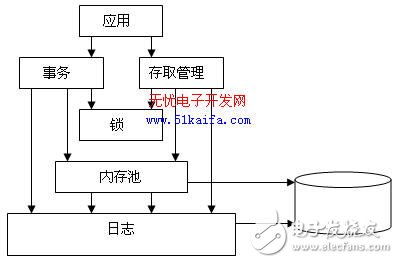
Figure 1 Berkeley DB subsystem diagram
1, Access Management Subsystems (Access Methods)
This subsystem provides basic support for creating and accessing database files. In the absence of transaction management, the modules in this subsystem can be used independently to provide applications with fast and efficient data access services.
2. Memory Pool Management Subsystem (Memory Pool)
This subsystem is the common shared memory buffer used by Berkeley DB. This subsystem can be used by the application alone.
3, TransacTIon
This subsystem provides transaction management functions for Berkekey DB, guaranteeing the principle of operation, consistency and isolation. The Transaction Subsystem is intended to be used where modifications to data that warrant transaction are required.
4, Locking System (Locking)
The subsystem provides concurrent management mechanisms between processes and within the process, providing the system with multiple user reads and single user modifications to the shared control of the same object. This subsystem can be used by the application alone.
5, Logging subsystem (Logging)
The subsystem adopts the strategy of first writing logs, supporting the transaction subsystem to perform data recovery and ensuring data consistency.
3 Application of Mass Storage Technology Based on Embedded Database in Network Performance Management System3.1 Embedded Database Berkeley DB Processing Massive Data Storage
Traditional network management software mostly uses large-scale relational databases for mass data storage. Because the network management software needs to communicate with the database server, this method results in a great decrease in system performance. In addition, the size of the managed network increases. With the rapid increase of information collection and the slow and frequent database read/write operations, it is impossible to process the massive data collected in real time, resulting in data loss, network management distortion, and even system defects. There are also a few network management software that use a log file to record the collected traffic data in the form of ASCII text. Usually this type of log file has a constant size feature that can support long-term network monitoring tasks, such as the most popular free of charge at home and abroad. The open source traffic monitoring software MRTG uses this method to achieve massive data storage. MRTG regularly integrates data and saves data with different granularity according to the date of recorded data. As time passes, the granularity of the corresponding data gradually becomes larger, but this method has two disadvantages: (1) Stored The data granularity is limited, for example, it is impossible to get the data for each half hour of the day from a month ago; (2) After each data acquisition, MRTG generates the traffic map according to the log file and renders it in HTML format. In practical applications, the probability that a port's traffic statistics analysis graphic is viewed by the user is far less than the probability that it is not invoked, thus wasting a lot of system overhead for generating graphics. With the expansion of the network size, MTRG is obviously in terms of performance. Can not meet the requirements. This article proposes a flow data acquisition and storage scheme as shown in Figure 2. The network performance management software receives the Netflow/sFlow packets sent from the router in real time (of course, this also includes the traffic data collected with the SNMP protocol), and stores the results in the embedded database Berkeley DB for long-term history preservation. Different from MRTG: (1) It uses the embedded database Berkeley DB, Berkeley DB can be directly connected to the internal application, and the application is running in the same address space, so it does not need to communicate with other database applications. Increased application speed, reduced disk operation time, and prevented data loss due to slow disk operations. (2) It does not generate graphs for each acquisition, but instead introduces “on-demand graphing†that triggers the control method. When the customer needs to check the graphs in a certain period of time, or the traffic of a certain port, or a certain kind of service When the graph is isochronous, it only needs to perform corresponding operations on the graphing control module, and the graphing module searches the database for specific data to generate corresponding graphs.
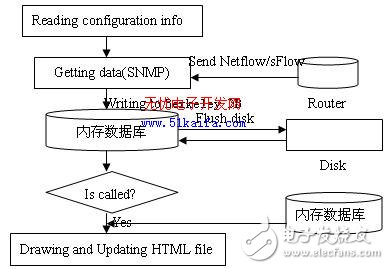
Figure 2 traffic data acquisition and storage scheme
3.2 Multi-process, multi-database locking mechanism for processing massive data in network performance management system
The premise of network management is information acquisition, collecting all information in a comprehensive and real-time manner, and then classifying the information, and then enabling the network management software to realize: real-time monitoring of network performance, real-time monitoring of system performance, real-time monitoring of application performance, and SLA service quality Management, fault early warning, DOS attack location, virus scanning, statistical analysis report, network capacity trend analysis, system management and maintenance. Since the capacity of a single database of Berkeley DB can only be 256T, and the network management information is huge, a method of multiple databases is adopted in order to expand its storage capacity. In addition, when customers use the graphing control module of the network performance management system software, they often pay attention to the graphs in a certain period of time such as: a port traffic graph in a certain period of time, a certain service graph in a certain period of time, and so on. Therefore, in order to map in the future, we set up several databases based on time (year, month, day). The database name is named for an hour (24-hour clock) on a certain day of the year in a certain year to store the information collected during the hour. In addition, in order to buffer the massive information collected in the network management, we adopt the message queue mechanism, and the parent process writes the collected information to the message queue first. Then the child process reads information from the message queue and writes it to the database (to prevent the message queue from having too many messages in a single process to read the message queue and write the database, causing the message queue to block, the overall system is inefficient. For this we have created multiple child processes. Read message queue to write database).
Use the above method to name the database in units of time (hours) and store the information in the corresponding time. However, due to occasional message retention (router residence time of up to 30 minutes, for example, 7:30 may be forwarded after 6:30), the router will be stored in a 7-point database. Distortion of storage information is not a true reflection of the network at a certain moment. To solve this problem, two databases are opened at a time, that is, both the database of the current point is opened and the database of the previous point of time is opened. When a packet is received, which database is written is determined based on the time at which the Netflow/sFlow stream in the packet arrives at the router.
Because of the above two reasons, there are multiple subprocesses in the system to write multiple databases. If you do not take certain measures, it is easy to have a series of problems such as: which process is responsible for creating the database, which process is responsible for closing the database, and how multiple processes are between management. To solve these problems, the system adopts a multi-process, multi-database locking mechanism and heartbeat mechanism.
Multi-process, multi-database locking mechanism to achieve the process shown in Figure 3

Figure 3 Multi-process, multi-database locking mechanism to achieve flow chart
3.3 Implementation of Multiple Additional Database Query Mechanisms
Since Berkeley DB is not a relational database, we cannot perform compound conditional query on it like a relational database. Frequent customers need to check the graph in a certain period of time, such as a port traffic graph and a certain period of time in a certain period of time. A certain kind of service graph, etc., and the graphing data of these graphs are all based on the compound condition query. To solve this problem Berkeley DB provides us with an attached database (secondary database). In the attached database we can set any key (can be a combination of multi-column attributes in a relational database), so we can use the key of the attached database. It is convenient to query in the additional database, obtain the required data and then display it in the graphing module. For this purpose, we have introduced 5 additional databases that are frequently used in the statistics of network traffic data and are easily searched by the module. They are: SCRIP_SUBDB, DSTIP_SUBDB, SRCPORT_SUBDB, DSTPORT_SUBDB, STARTTIME_SUBDB. And according to the actual situation we can also increase the number of additional databases. In addition, in order to improve the database query efficiency and data insertion speed, combined with Berkeley DB's four access methods, we use the Queue access method for the main database to increase data insertion speed, and use time as the key. For the additional database, we use the BTree access method to improve query efficiency, and the key is generated based on different correlation functions. Here we use the attached database SCRIP_SUBDB as an example to discuss the relationship between the primary database and the attached database:
Initenv(const conf_ST *conf)//initialize the database environment
Initalldb (const conf_ST *conf, int type) // Initialize all databases
{
⋯⋯
Init_primary_db(conf, &last-db,LAST,type);//initialize the database before a point in time
Init_primary_db(conf,&(current-db),CURRENT,type); //initialize the current point in time database
⋯⋯
INIT_SEC_DB(srcip,SRCIP,type); //this function is actually a macro defined to initialize the attached database
⋯⋯
}
Int get_item_srcip(DB *sdbp, const DBT *pkey, const DBT *pdata, DBT *skey)
//Associating function of attaching database to main database setting key
Int init_sub_db(const conf_ST *conf, DB**primary_db, DB **sub_db, int sub_db_type, int\TIme_db_type, int type) // Initialize additional databases
{
⋯⋯
Ret = (*primary)-"associate(*primary_db,NULL,*sub_db,get_item_srcip,\
DB_CREATE); // Call the Berkeley DB system function to attach additional data to the primary database and set the key in the attached database
⋯⋯
}
⋯⋯
4 Summary:The author of this article innovates that during the development and practice of the project, we write the relational database Mysql and the embedded test database BerkeleyDB with different orders of magnitude respectively. It is found that the introduction of the embedded test database Berkeley DB greatly improves the system's storage speed, making The access time is reduced by several times. From this perspective, the embedded database Berkeley DB has advantages in time and speed compared with relational databases in processing massive data storage, but the information collected in the network management performance system is huge, how to store the massive amount of data in the Berkeley DB database. Data compression is still a question worth exploring.
We supply China 2022 Newest Rechargeable Vape 5000 Puffs Mesh Coil Disposable Wholesale Disposable Vape Pen, Find details about China 5000 Puffs Vape from 2022 Newest Rechargeable Vape.
Fair price and high quality products. we sell many well-known brand products. You can definitely find what you want in tsvping.com.e are a vape (ecigarette) factory located in China.
Wholesale Supply OEM/ODM 5000 Puffs Disposable Vape Pod Device.
Vape 5000 Puffs,Disposable Vape 5000 Puffs,E Cigarette Juice,E Cigarette Liquid
TSVAPE Wholesale/OEM/ODM , https://www.tsecigarette.com