Microsoft researchers published a blog post on March 14 stating that progress has been made in translating texts using deep neural network artificial intelligence (AI) training techniques. They invented the first machine translation system that can translate Chinese news sentences into English, with the same accuracy as humans. The system achieved a human level on a set of commonly used news report test sets, and the test set was called newstest2017.
In the previous articles, we introduced the contents of neural networks and deep learning. Microsoft's translation system uses deep neural networks to help generate more realistic and accurate translations. It also uses a variety of different artificial intelligence training methods, including double-learning, deliberative networks, and joint training, in an attempt to imitate human learning.

machine translation
A machine translation system is a process that supports the translation of a large number of text applications or online services, and the translation of text from a "source" language to another "target" language.
Since the early 2010s, the new artificial intelligence technology - deep neural network (also known as deep learning) has reached a high level of accuracy. The Microsoft translation team has combined speech recognition with its core text translation technology to introduce new speech translation technologies.
Although the concept of machine translation technology and interface technology is relatively simple, the integration of technology behind it is extremely complex, integrating a number of cutting-edge technologies, especially deep learning (artificial intelligence), big data, linguistics, cloud computing and web API.
Historically, the once-mainstream machine learning technology used in the industry was statistical machine translation (SMT). SMT uses advanced statistical analysis to estimate the best possible translation from a few words in the context. SMT has been used by all major translation service providers since the mid-20th century, including Microsoft.
The emergence of translation technology based on deep neural network (NN) has led to a sudden change in machine translation technology, which has significantly improved translation quality. This new translation technology will begin to be deployed on a large scale in the second half of 2016.
There are two aspects common to these two technologies:
Both require a large amount of human-translated data (up to millions of manually translated sentences) to train the translation system.
Neither as a bilingual dictionary nor a translation list is translated according to the context in which the word is used in the sentence.
Microsoft Translation
Microsoft's translation of text and voice APIs is part of the Microsoft Cognitive Services Collection and is Microsoft Cloud's machine translation service.
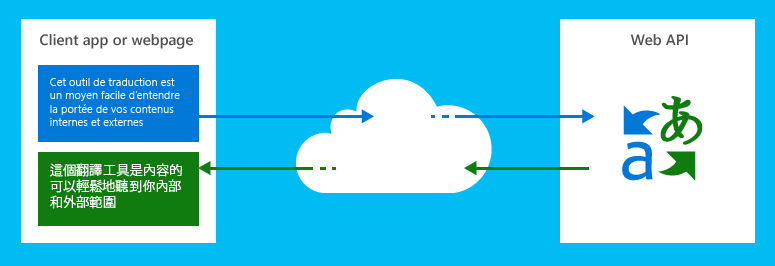
1, Microsoft Translation Text API
The Microsoft Translated Text API has been used in products and services from multiple Microsoft business units since 2006 and has been available to third-party customers since 2011. The Microsoft Translation Text API has been widely used within Microsoft Corporation. It is used for product localization, customer support, and online communication (for example, Windows Blog). This service can also be accessed from familiar Microsoft products (Bing, Cortana, Internet Explorer, Lync, Cortana, Office, SharePoint, Skype, and Yammer) at no additional charge.
Microsoft Translator can be used on the web or client in any hardware platform, combined with any operating system for language translation and other language related operations such as text language detection, text to speech conversion, and dictionaries.
Using industry-standard REST technology, developers send source text to the service and identify the parameters of the target language. The service translates the translated text back to the client or web application.
Microsoft's translation service is deployed in the Microsoft data center and enjoys the same benefits as other Microsoft cloud services in terms of security, scalability, reliability, and continuous availability.
2. Microsoft Translate Voice API
Microsoft's voice translation technology was first introduced through Skype Translator integration at the end of 2014, and in early 2016 it was offered as an open API to customers. It is integrated in Skype, Skype Conference Broadcast and Microsoft Translation App (Android, iOS and Windows).
How does text translation work?
There are two main types of machine translation technologies: traditional statistical machine translation (SMT) and a new generation of neural network (NN) translation.
1, statistical machine translation
The statistical machine translation (SMT) used by Microsoft's translators is based on more than a decade of Microsoft's natural language processing research. Modern translation systems no longer write rules manually for language conversion. Instead, they treat translation as a learning problem based on the existing manual translation and transformation of all languages ​​and take advantage of the latest results in applied statistics and machine learning.
The so-called "parallel corpus" largely acts as the modern Rosetta Stone, which provides translations of words, phrases and idioms for many languages ​​and specialized fields based on context. Statistical modeling techniques and efficient algorithms help solve the problems of computer interpretation (detection of the correspondence between source and target language in training data) and decoding (find the best translation for new input sentences). Microsoft Translator combines the power of statistical methods with linguistic information to produce more ideal translations and easier to understand output.
Since this method does not rely on lexicographic or grammatical rules, it provides vocabulary and phrases that are optimally translated based on context.
2, neural network translation
The continuous improvement of translation quality is very important. However, performance improvement of SMT technology has stagnated since the mid-2010s. Through large-scale deployments of Microsoft AI supercomputers, and in particular through the Microsoft Cognitive Toolkit, Microsoft Translator now offers neural network (LSTM)-based translations, which has improved the quality of translation into a new decade.
These neural network models have been deployed in all Microsoft speech translations and can be invoked via the speech translation API, or via the text API using the "generalnn" Category ID parameter.
The fundamental implementation of neural network translation is different from traditional SMT translation.
The following animation describes the various steps of neural network translation. Using this approach, translation will take into account context-complete sentences, whereas SMT technology can only consider several words in the context. Therefore, neural network translation will produce more fluent and close to human translation results.
Based on neural network training, each word is encoded along a 500-dimensional vector (a) to represent its unique characteristics for a particular language pair (eg, English and Chinese). Using language pairs for training, the neural network will customize what these dimensions should be. They can deal with simple concepts such as gender (female, male, neutral), politeness levels (slang, casual, written formal, etc.), types of words (verbs, nouns, etc.), and any other non-obvious features. Coded as derived training data.
The steps of the neural network translation run are as follows:
Each word or, more specifically, the 500-dimensional vector represents it, passing through the "neuron" of the first layer, and will encode it in a 1000-dimensional vector (b) representing the range of other words in the context sentence of the word.
Once all words have been coded for these 1000-dimensional vectors, the process is repeated several times and each layer is fine-tuned better. This 1000-dimension represents the complete sentence of the word (while SMT translation only considers 3 to 5 words Within the window).
The translation attention layer (ie, the software algorithm) will use this final output matrix and previously translated words to determine which word from the source sentence should be next to the final output matrix. It will also use these calculations to remove unnecessary words in the target language.
The decoder (translation) layer, in its most suitable target language, converts the selected word equivalently (or, more specifically, the 1000-dimensional vector represents the complete sentence range of the word). This output layer (C) is then fed back to the attention layer to calculate the next word that the source sentence should translate.

In the animated example, the context-aware 1000-dimensional model of "the" would encode a house that is a French female word (la maison). This translates "the" as appropriate to "la" instead of "le" (singular, male) or "les" (plural) when it reaches the decoder (translation) layer.
Note that the algorithm will also calculate based on previously translated (in this case "the"), the next word translated should be the subject ("house") rather than an adjective ("blue"). This can be done because the sequence of words in these sentences was systematically studied when translating English and French. If the adjective is "big" rather than a color adjective, it should not be reversed ("the big house" => "la grande maison").
The final translation results based on this approach are, in most cases, smoother and closer to human translation than SMT-based translations.
How does speech translation work?
Microsoft Translator can also translate speech. This feature was originally available only through the Skype Translator, as well as the iOS and Android Microsoft Translator applications. It is now available to developers through the latest version of the speech translation API.
Although it may seem like a simple process at first glance, it is much more complicated than merely inserting the “traditional†man-machine speech recognition engine into an existing text translation engine.
To correctly translate a "source" speech from one language into a different "target" language, the system goes through a four-step process.
Speech recognition converts audio to text.
TrueText Algorithm: Microsoft's unique technology optimizes spoken language to more standard text, making it more suitable for machine translation.
Through the above-mentioned text translation engine for translation, a translation model developed for a real-life spoken language conversation is utilized.
Text-to-speech, if necessary, output audio of the translation.

1. Automatic Speech Recognition (ASR)
Automatic speech recognition (ASR) is performed using a DNN system that has been trained for thousands of hours. This model is based on human and human interaction data, rather than human-machine instruction training, which can produce speech recognition effects suitable for normal conversation optimization. In order to achieve this goal, DNN needs more and more living spoken data training systems than traditional human-computer interaction ASR.
2, TrueText
Our daily speech is not perfect, and often not as clear and fluent as I think. With TrueText technology, it is possible to remove irreconcilable parts of the spoken language (verbs such as "uh", "ah", "and", "for example"), stuttering and repetition to make the text more closely reflect the user's intentions. It also makes the text easier to read and easier to translate by adding segmentation, correct punctuation, and capitalization. To achieve these results, we have applied decades of research results to the development of Translator's language technology to create TrueText. The following figure shows the implementation of TrueText through a real example.
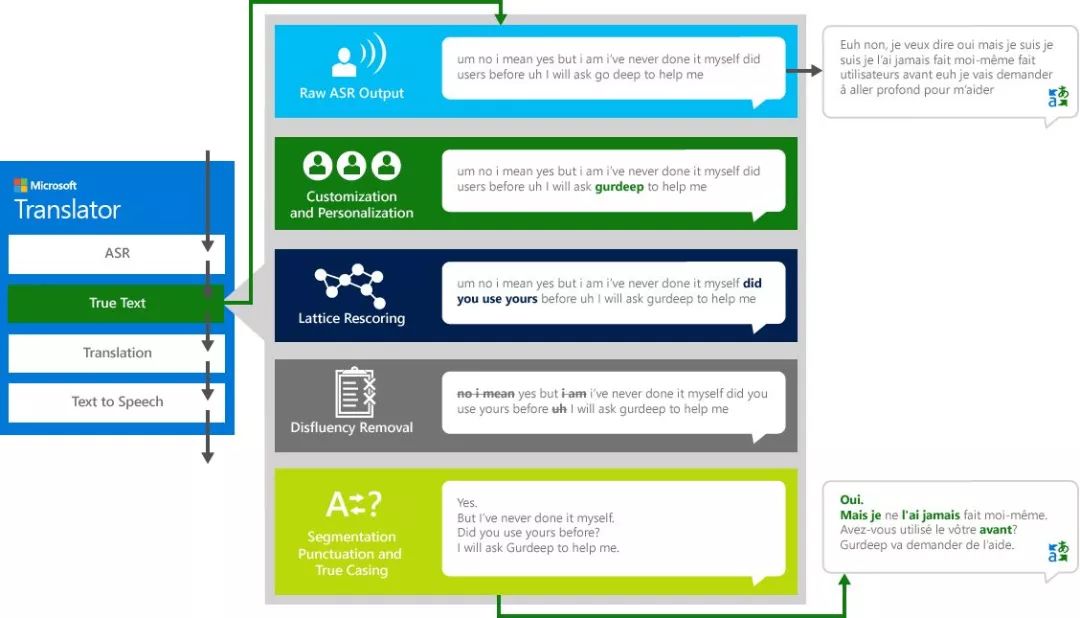
3, translation
Then translate the relevant text into any of the more than 60 languages ​​supported by Microsoft's translation.
The language translation API for developers or the use of the latest neural network translations in speech translation applications or services can use all speech input supported languages ​​(see full list here). Most of the existing translation models are written language and text training. By adding more oral text corpora, a better model for the translation of spoken language conversation types is established. These models are also available through the 'Speech' standard text translation API.
For any other non-voice-supported languages, traditional SMT translations are still used unless otherwise stated here.
4, text to speech
Currently we support 18 text-to-speech languages. If audio output is required, the text will be output as speech synthesis. This phase will be omitted in the context of speech-to-text translation.
Newstest2017 system new technology
According to the official Microsoft blog, four new technologies are used in the new translation system: dual learning, joint training, network optimization, and consistency regularization. The corresponding paper has also been published.
1, Dual Learning Desk (Dual Learning)
Dual learning uses the natural symmetry of artificial intelligence tasks. Its discovery is due to the fact that meaningful and practical artificial intelligence tasks often appear in pairs, and the two tasks can be fed back to each other to train a better deep learning model. For example, in the field of translation, we are concerned with translating from English to Chinese, and we are equally concerned with translating from Chinese to English. In the field of speech, we are concerned with both speech recognition and speech synthesis. In the field of images, image recognition and images Generation also occurs in pairs. In addition, there are dual tasks in scenarios such as dialogue engines and search engines.
On the one hand, due to the existence of a special dual structure, two tasks can provide feedback information to each other, and these feedback information can be used to train deep learning models. In other words, even if there is no artificially annotated data, deep learning can be done with the dual structure. On the other hand, two dual tasks can act as each other's environment, so that it is not necessary to interact with the real environment. The interaction between two dual tasks can produce effective feedback signals. Therefore, to fully utilize the dual structure, it is expected to solve the bottleneck of deep learning and enhanced learning, such as "what does the training data come from and how does the interaction with the environment continue?"
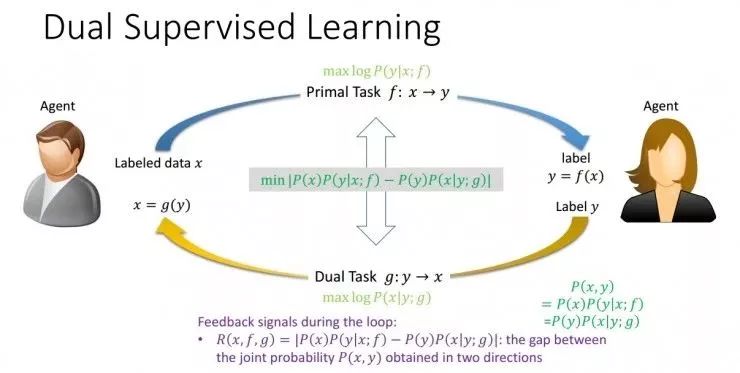
Illustration of the paradigm of ICML 2017 dual supervised learning paper
2. Deliberation Network
The word "deliberation" can be thought of as a form of behavior that occurs when humans read, write articles, and perform other tasks. That is, after the mission is completed, it does not end immediately, but it is repeated. The Microsoft Research Institute for Machine Learning team used this process in machine learning. It is assumed that the network has two stages of decoders, wherein the first stage decoder is used for decoding to generate the original sequence, and the second stage decoder polishes and polishes the original sentence through the process of scrutiny. The latter understands the global information. In machine translation, it can generate better translation results based on the statements generated in the first stage.
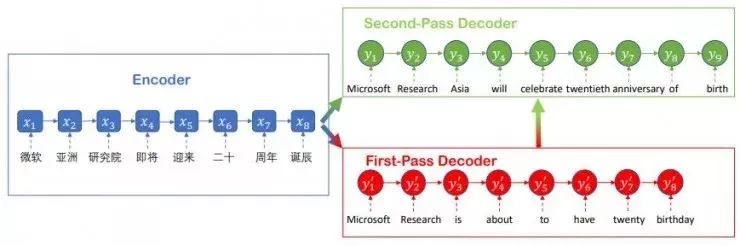
3ã€Joint Training
This method can be considered as a combination of learning from source language to target language translation and learning from target language to target to source. Chinese-English translation and English-Chinese translation both use initial parallel data to train. In each iteration of training, the Chinese-English translation system translates Chinese sentences into English sentences so as to obtain new sentence pairs, which in turn can be translated into English. Added to the data set of the English-Chinese translation system. In the same way, this process can also be reversed. This two-way fusion not only greatly increases the training data sets of the two systems, but also significantly increases the accuracy.
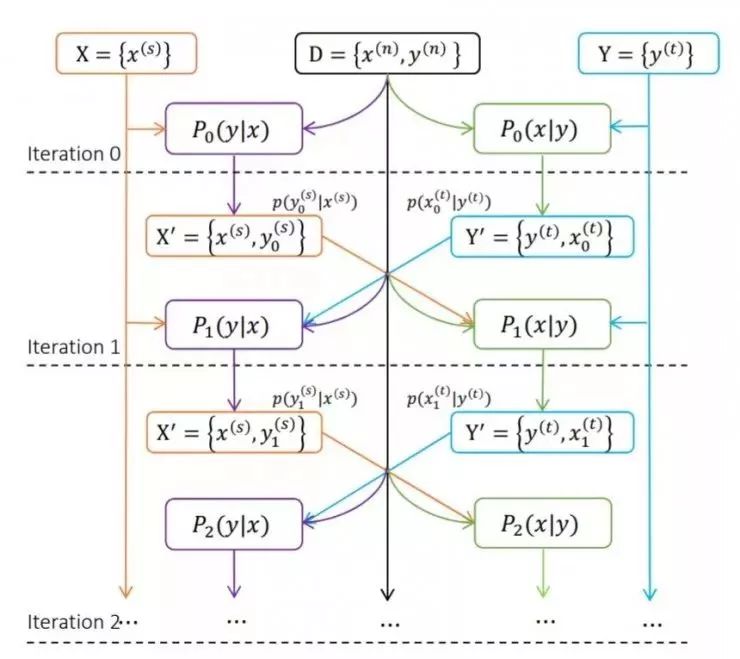
From source language to target language translation (Source to Target) P(y|x) and from target language to Target Language Source Source P(x|y)
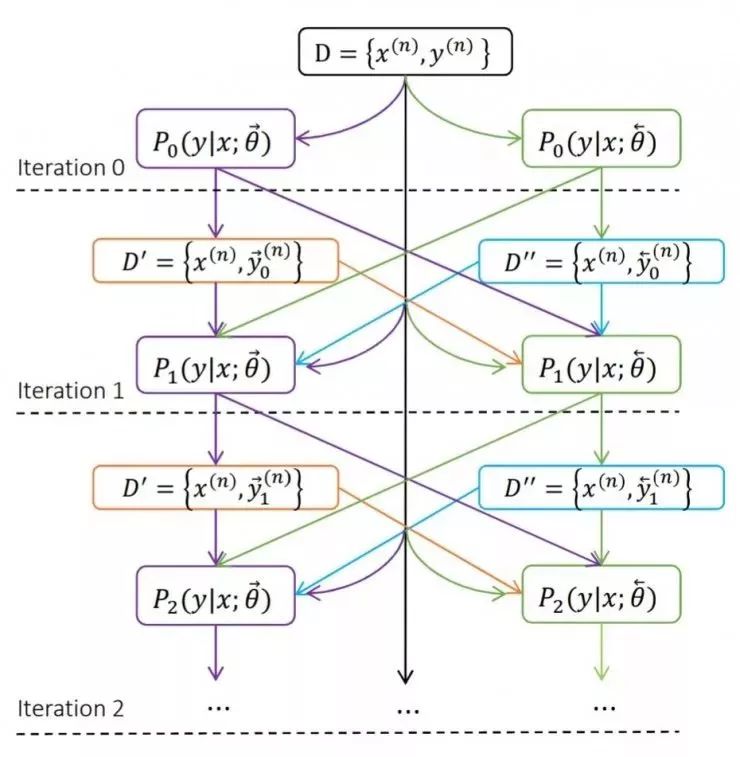
4. Agreement Regularization
Translation results can be generated from left to right in order, or from right to left. The specification constrains the translation results from left to right and from right to left. If the translation results produced by these two processes are the same, it is generally more credible than a translation with different results. This constraint applies to the neural machine translation training process to encourage the system to generate consistent translation results based on these two opposite processes.
Complexity makes machine translation a very challenging issue, but it is also a very significant issue. Liu Tieyan, deputy dean of the Microsoft Asia Research Institute and head of the machine learning group, believes that we do not know the day when the machine translation system will be able to translate any language, any type of text, into multiple dimensions such as “Xin, Da, Yaâ€. On the level of professional translators. However, he is optimistic about the progress of technology, because each year Microsoft's research team and the entire academic community will invent a large number of new technologies, new models and new algorithms. "We can predict that the application of new technologies will definitely make machine translations. The results are improving."
Fiber Optic Cable Equipment,Fiber Optic Cable Splicing Equipment,Fiber Optic Cable Installation Equipment,Fiber Optic Cable Testing Equipment
Huizhou Fibercan Industrial Co.Ltd , https://www.fibercannetworks.com