Recently, I used my spare time and re-examined Storm. Seriously comparing Hadoop, the former is better at real-time streaming data processing, the latter is better at HDFS, offline data analysis and calculation through MapReduce. For Hadoop, it is not good at real-time data analysis processing. The commonality between the two is a distributed architecture, and they all resemble the concept of a master/slave relationship.
In this article, I will not elaborate on how to deploy Storm cluster and Zookeeper cluster. I want to use a practical case to analyze how to use Storm to complete real-time analysis and processing data.
Storm itself is an open source distributed real-time computing system hosted by Apache. Its predecessor is Twitter Storm. Before Storm came out, dealing with massive amounts of real-time data information was mostly similar to using message queues, plus the way work processes/threads. This makes building such applications extremely complicated. In many business logics, you have to consider issues such as sending and receiving messages, concurrency control between threads, and so on. The business logic may only occupy a small part of the entire application, and it is difficult to decouple the business logic. But the emergence of Storm has changed this situation. It first abstracts the abstract concept of the data stream Stream. A Stream refers to the unbounded sequence of tuples. The concept of Spouts and Bolts continues to be introduced later. Spouts is a data source in Storm and is responsible for generating streams. Bolts takes the stream as input and regenerates the stream as output, and Bolts continues to specify how the stream it enters should be divided. Finally, Storm is a distributed data processing network composed of several Spouts and Bolts through the abstract concept of Topology. When Storm designed, it intentionally encapsulated the Topology network composed of Spouts and Bolts through the Thrift service. This method enables Storm's Spouts and Bolts components to be implemented in any mainstream language, making the entire framework compatible. Sex and scalability are even better.
The concept of Topology in Storm is very similar to the concept of MapReduce Job in Hadoop. The difference is that Storm's Topology will run as long as you start it, unless you kill it; the MapReduce job will end up. Based on such a model, Storm is well suited for processing real-time data analysis, continuous computing, DRPC (Distributed RPC), and the like.
The following is a combination of actual cases, design analysis, how to use Storm to improve the processing performance of the application.
A spam monitoring platform of a communication company uploads spam text file of suspected spam users in each province in real time, and each province analyzes and filters out spam messages containing sensitive keywords according to the contents of spam messages in the file. Carry in the warehouse. The spam users who are warehousing are listed as sensitive users, which are the key monitoring objects. After all, it is very wrong to send these spam messages. The file speed generated by the spam monitoring platform is very amazing. The original traditional practice is to serially parse and filter sensitive keywords according to each independent market in each province to perform inbound processing. However, from the current situation, the performance of program processing is not efficient, often resulting in a backlog of files, not processed in time.
Now, we will reorganize and organize the above application scenarios through Storm.
First, let me explain the deployment of the Storm cluster and the Zookeeper cluster in this case, as shown in the following figure:
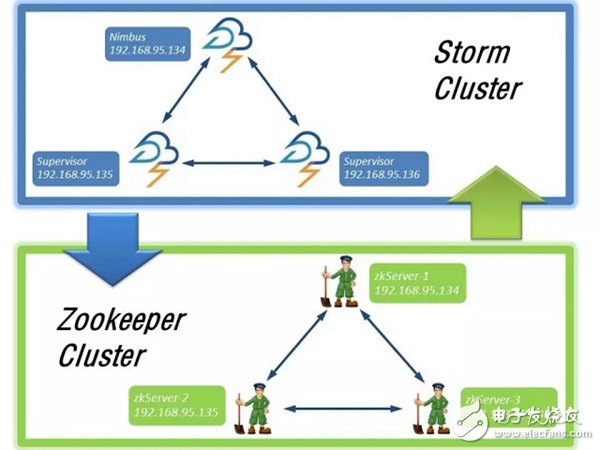
The host corresponding to Nimbus is 192.168.95.134 is the main node of Storm, and the hosts corresponding to the other two slave nodes are 192.168.95.135 (host name: slave1) and 192.168.95.136 (host name: slave2). Similarly, the ZooKeeper cluster is also deployed on the above nodes.
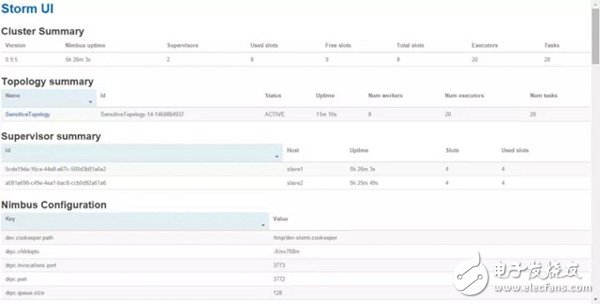
The Storm cluster and the Zookeeper cluster will communicate with each other because Storm is based on Zookeeper. Then start the ZooKeeper service of each node first, and then start the Nimbus and Supervisor services of Storm respectively. Specifically, you can start the service under the bin directory of the Storm installation. The startup commands are storm nimbus †/dev/null 2 ​​》 &1 & and storm supervisor †/dev/null 2 ​​》 &1 &. Then use jps to observe the effect of the startup. If there is no problem, start the Storm UI monitoring service on the host corresponding to the Nimbus service. In the bin directory of the Storm installation directory, enter the command: storm ui â€/dev/null 2â€&1 &. Then open the browser input: http://{Nimbus service corresponding host ip}: 8080, here is the input: http://192.168.95.134:8080/. Observe the deployment of the Storm cluster, as shown in the following figure:
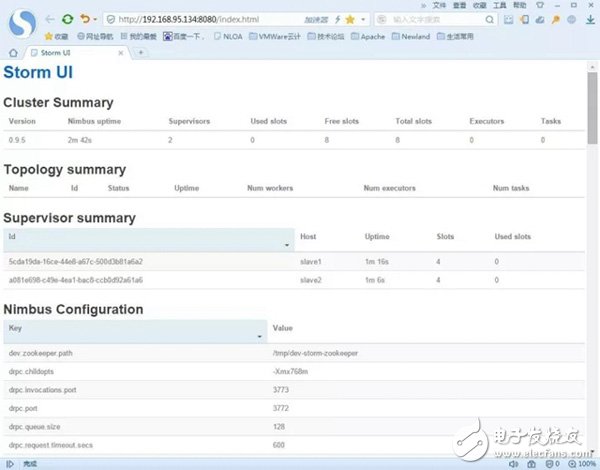
It can be found that the version of our Storm is 0.9.5, and there are two slaves (saveve1, slave2). The total number of wokers is 8 (Total slots). The Storm cluster has been deployed and it has been successfully launched. Now use the Storm method to rewrite the application of this sensitive information real-time monitoring and filtering. First look at the topology diagram of the Storm mode:
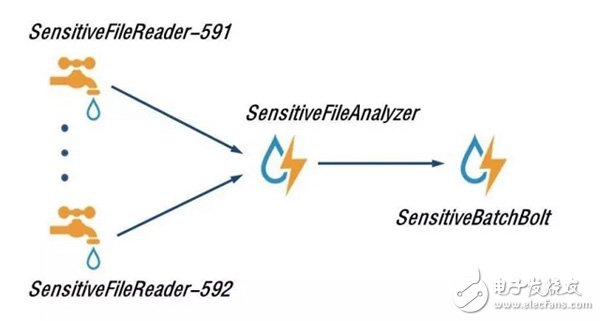
Among them, SensiTIveFileReader-591 and SensiTIveFileReader-592 (user SMS collector, sub-district city) represent the Spouts component in Storm, which represents the source of a data. Here, it means to read the suspected spam user from the specified directory of the server. Spam text content files. Of course, the components of Spouts can extend a lot of Spouts according to actual needs.
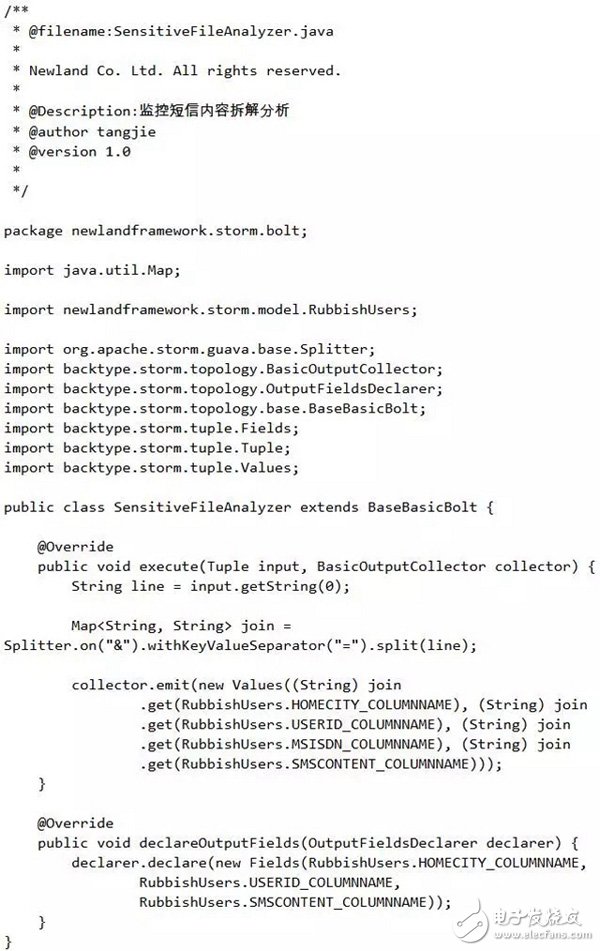
After reading out the contents of each line in the file, it analyzes the content component of the file. Here is: SensiTIveFileAnalyzer (monitoring SMS content disassembly analysis), which is responsible for analyzing the format of the file.
For the sake of a simple demonstration, the format of the file I defined here is as follows (just write an example): home_city=591&user_id=5911000&msisdn=10000&sms_content=abc-slave1. Use & to connect between each column. The home_city=591 indicates the user's attribution city code of the suspected spam message, 591 indicates that Fuzhou, 592 indicates Xiamen; user_id=5911000 indicates the user ID of the suspected spam message; msisdn=10000 indicates the mobile phone number of the user suspected of spam; sms_content=abc- Slave1 represents the content of spam messages. SensiTIveFileAnalyzer represents the Bolt component in Storm, which is used to process the data streamed by Spouts.
Finally, we filter the sensitive keywords based on the parsed data and match the business rules. Here we are storing the filtered data in the MySQL database. The component responsible for this task is: SensitiveBatchBolt (sensitive information collection processing), of course, it is also the Bolt component in Storm. Ok, the above is the complete Storm topology.
Now, after we have a whole understanding of the topology of the entire sensitive information collection and filtering monitoring, let's look at how to implement the specific coding! Let's first look at the code hierarchy of the entire project, as shown in the following figure:

First of all, we define the data structure of the sensitive user RubbishUsers, assuming that the sensitive content of the sensitive users we want to filter, including "racketeer", "Bad" and other sensitive keywords. The specific code is as follows:

Now, let's look at the specific implementation of SensitiveFileReader, a sensitive information data source component. It is responsible for reading the spam text file of suspected spam users from the specified directory of the server, and then sending the data of each line to the next processed Bolt. (SensitiveFileAnalyzer), after the end of each file is sent, in the current directory, rename the original file to the suffix bak file (of course, you can re-create a backup directory, specifically for storing this processed file), The specific implementation of SensitiveFileReader is as follows:
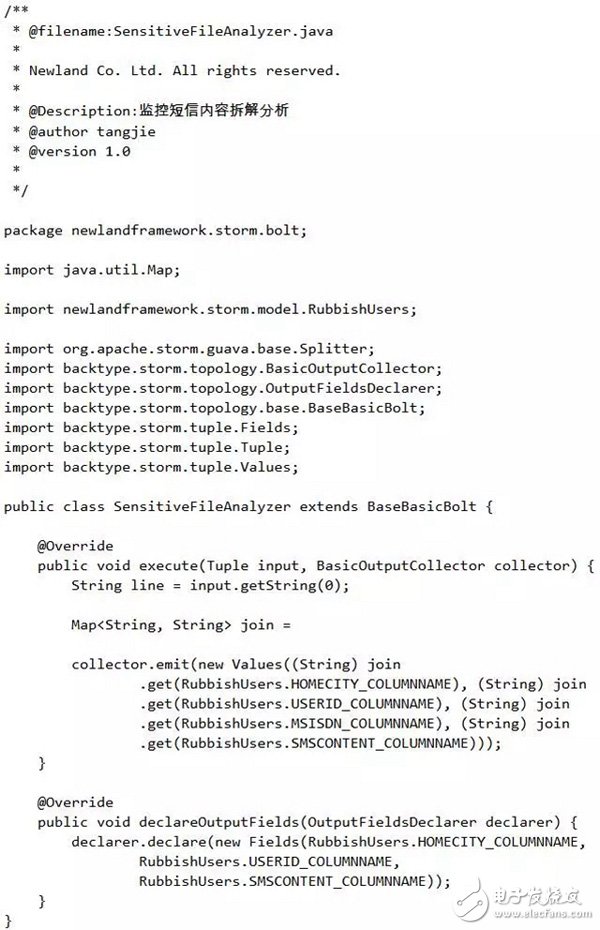
Monitor the SMS content disassembly analyzer SensitiveFileAnalyzer. After receiving the data of the data source SensitiveFileReader, the Bolt component parses the content of each line in the file according to the format defined above, and then sends the parsed content to the next. A Bolt component: SensitiveBatchBolt (sensitive information collection processing). Now let's take a look at the implementation of the SensitiveFileAnalyzer Bolt component:
The last Bolt component SensitiveBatchBolt (sensitive information collection processing) is based on the data sent by the upstream Bolt component SensitiveFileAnalyzer, and then matched with the sensitive keywords specified by the service. If the matching is successful, the user is the user we want to monitor, we put It collects MySQL database through hibernate and manages it uniformly. Finally, the SensitiveBatchBolt component also implements a monitoring function that periodically prints out the sensitive user data we have collected. Now give the implementation of SensitiveBatchBolt:

Since it is imported into MySQL via hibernate, the hibernate configuration is given, first: hibernate.cfg.xml

The corresponding ORM mapping configuration file rubbish-users.hbm.xml reads as follows:

Finally, hibernate is integrated through Spring, the database connection pool is: DBCP. The corresponding Spring configuration file jdbc-hibernate-bean.xml has the following contents:

So far, we have completed the development of all Storm components for real-time monitoring of sensitive information. Now, we will complete the Storm topology. Since Topology is divided into local topology and distributed topology, a tool class StormRunner (topology executor) is encapsulated. The corresponding code is as follows:

Ok, now we've stitched all of the above Spouts/Bolts into a "Topology" structure, and we're using a distributed topology for deployment. The specific SensitiveTopology code is as follows:

At this point, all Storm components have been developed! Now, we put the above project into a jar package and put it into the Storm cluster. You can go to the bin directory under the Storm installation directory of Nimbus and type: storm jar + {jar path}.
For example, here is the input: storm jar /home/tj/install/SensitiveTopology.jar newlandframework.storm.topology.SensitiveTopology, and then put the junk SMS content file of the suspected spam user to the directory under the specified server (/home/ Tj/data/591, /home/tj/data/592), finally open the Storm UI and observe the startup execution of the task, as shown below:
You can see the topology we just submitted: SensitiveTopology has been successfully submitted to the Storm cluster. At this time, you can click on SensitiveTopology and then open the following Spouts/Bolts monitoring interface, as shown below:
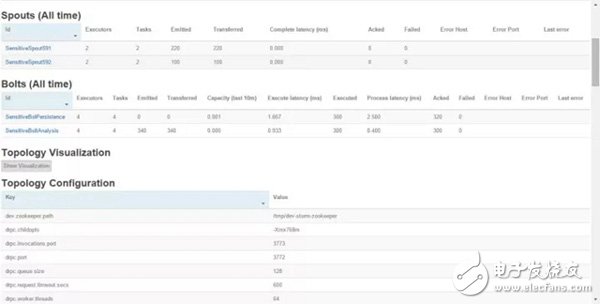
We can clearly see: Spouts component (user SMS collector): SensitiveFileReader591, SensitiveFileReader592 thread number executors, task submission emitted case. And the Bolts component: monitors the operation of the SMS Content Disassembly Analyzer (SensitiveFileAnalyzer) and SensitiveBatchBolt, which makes monitoring very convenient.
In addition, we can also go to the logs directory under the Storm installation directory corresponding to the corresponding Supervisor server to view the work log of the worker. Let's take a look at the processing of sensitive information monitoring and filtering. The screenshots are as follows:
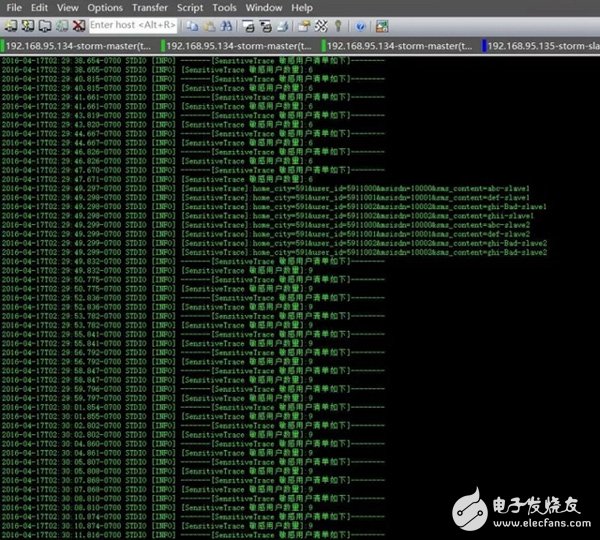
Through the monitoring thread of the SensitiveBatchBolt module, we can see that we have collected 9 sensitive information users. Then, are these users with sensitive keywords successfully logged into MySQL?
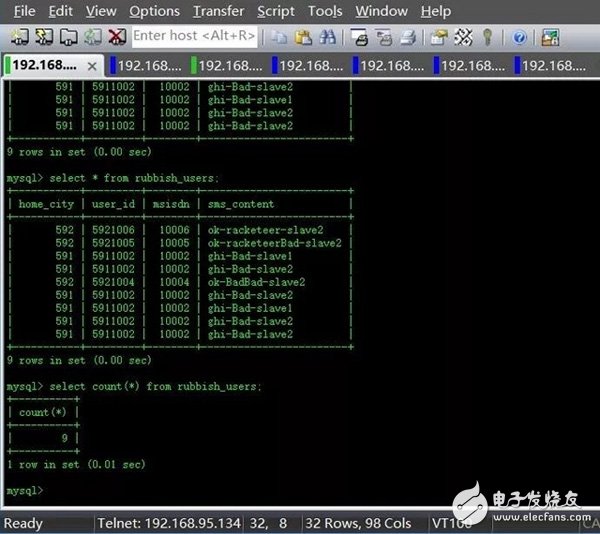
The result of the discovery of the warehousing is also nine, which is consistent with the number of log prints. And the spam content sms_content really contains sensitive keywords such as "racketeer" and "Bad"! Fully in line with our expectations. Moreover, after the amount of file processing has come up, we can adjust the parallelism of Spouts/Bolts and the number of Workers. Of course, you can also solve this problem by horizontally expanding the number of clusters.
Intel I5 Laptop is the one of the important high cpu processors, another ones are i3, i7, i9. We can do 2th, 4th, 5th, 6th, 8th, 10th, 11th or 12th. How to choose a best suitable one? If you do heavier jobs, like interior design, music or video editing, even engineering drawing, etc, 15.6 inch Intel I5 11th Generation Laptop or Intel I5 10th Generation Laptop is a better choice for you. If you focus on portability, Laptop 14 Inch I5 11th generation is a good option. Of course, Intel i7 11th Generation Laptop or 1650 graphics card laptop also available.
Someone may worry the custom one quality, that`s cause that lack of custom Student Laptop knowledge, so just keep reading so that know deep in this field. Frankly speaking, the technical skill is totally mature, no matter hardware or software or craft. You can see nearly no difference when check the oem laptop and brand one in person. To support clients and be confident with our product, provide sample for every clients.
Any other special requirements, you can just contact us freely or email us and share the exact details about what you need, thus right and valuable information sended in 1 working day.
Intel I5 Laptop,Intel I5 11th Generation Laptop,Intel I5 10th Generation Laptop,Laptop 14 Inch I5,Intel I5 Laptop Price
Henan Shuyi Electronics Co., Ltd. , https://www.shuyiminipc.com