Face recognition technology has been widely used, and the technology behind the large-scale domestic surveillance system is face recognition.
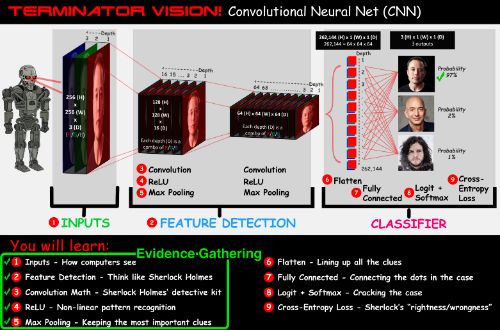
Different from the conventional neural network method for facial recognition, the author of this article, Dave Smith, took an unusual path. He built a CNN neural network for facial recognition in 9 steps in Excel and let the detective Sherlock recognize The terminator of the world "Elon"! In this article, the author tries to show what is happening behind the code in an intuitive and visual way, hoping to help you eliminate some doubts in the learning process.
The goal of this article is to provide you with a simple introduction to machine learning, which will cover the 9 steps shown in the figure below.
Supplementary tool: to help you understand how to convert any picture into an Excel file with conditional format in about 30 seconds
http://think-maths.co.uk/spreadsheet

Terminator perspective-create a convolutional neural network in a spreadsheet
background
Let us first assume that there is a special detective named'Sherlock Convolution Holmes' in the Terminator's brain. His job is to look carefully at the evidence (input image) and use keen eyes and deduction ability (feature detection) to predict who the person in the picture is in order to solve the case (correct image classification).
Note: In order to reduce everyone's doubts about the following content, first of all spoiler, the "male protagonist" of this article is actually Sherlock Convolution Holmes. The author may be a fan of the detective Sherlock, and the whole article revolves around how Sherlock solved the case.
We will use the spreadsheet model to view the picture, analyze the pixel value, and predict whether it is Elon Musk, Jeff Bezos or Jon Snow. Obviously these three people are Skynet's biggest threats. To use the image metaphor, CNN is like Sherlock Holmes. Some mathematical formulas will be used in this process. We have given a reference link here for everyone to learn.
Reference link:
https://drive.google.com/open?id=1TJXPPQ6Cz-4kVRXTSrbj4u4orcaamtpGvY58yuJbzHk
Each of the following 9 steps is part of this pictorial metaphor.
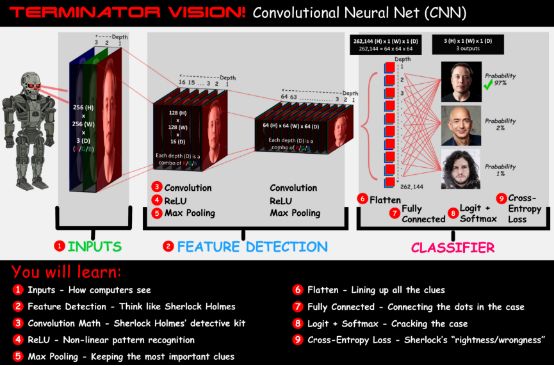
Convolutional Neural Network Architecture
first step

â–ŒInput: A picture is like thousands of numbers
Below is our input picture. How do we manipulate this picture?


Think of digital photos as 3 spreadsheets (1 red, 1 green, and 1 blue) stacked together, each of which is a matrix of numbers. When taking a picture, the camera measures the amount of red, green, and blue light for each pixel. Then, rank each pixel on a scale of 0-255 and record them in the spreadsheet:

In the above 28x28 image, each pixel is represented by 3 rows (1 red, 1 blue, and 1 green), and its value is 0-255. The pixels have been formatted according to their values.

I didn’t see the real eyes, all I saw was a bunch of numbers
If we divide each color into a separate matrix, we will get three 28x28 matrices, and each matrix is ​​the input for training the neural network:

Model input
â–ŒTraining overview
When you were just born, you didn't know what a dog was. But as you grow up, your parents will show you photos of dogs in books, cartoons, and in real life. Eventually you can point to those four-legged furry animals and say "this is a dog". This is because the connections between billions of neurons in the brain have become strong enough for you to recognize dogs.
The Terminator learns who Elon is in the same way. Through a supervised training process, we showed it thousands of photos of Elon Musk, Jeff Bezos and Jon Snow. At first, it has a one-third chance of guessing, but like a child, this chance will increase over time. The network connection or "weight/bias" will be updated over time, making it possible to predict the output of the picture based on the pixel-level input.

So what makes convolutional neural networks different from ordinary neural networks?
5 words: translation invariance. Let's analyze it briefly:
Translation = move from one place to another
Immutability = remain unchanged
For computer vision, this means that no matter where we move the target (translation), it will not change the content of the target (immutability).

Translation invariance (scale invariance can also be added)
No matter where he is in the image (translation), what size (the scale does not change), the convolutional neural network can recognize Elon's features after training. CNN is good at identifying patterns in any part of an image, and then superimposing these patterns together to build more complex patterns, just like humans.
In ordinary neural networks, we treat each individual pixel as the input of our model (instead of 3 matrices), but this ignores that adjacent pixels have special meaning and structure. For CNN, we focus on groups of pixels adjacent to each other, which allows the model to learn local patterns like shapes, lines, etc. For example, if CNN sees many white pixels around a black circle, it will recognize this pattern as an eye.
In order for CNN to achieve translation variance, they must rely on feature detection, which is Sherlock Convolution Holmes.
Second step

â–ŒFeature detection: meet Sherlock Convolution Holmes
Sherlock uses a magnifying glass to carefully examine each image to find important features or "clues" in that image. Then stack these simple line and shape features together, and you can start to see facial features like eyes or nose.

Each convolutional layer will contain a bunch of feature maps or "clues" constructed with each other. After all the convolutions are completed, he puts all these clues together to crack the case and correctly identify the target.
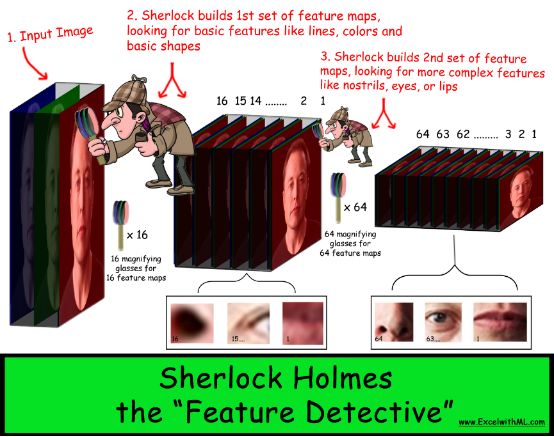
Each feature map is like another "clue"
Each convolutional layer of the network has a set of feature maps, which use a layered approach to identify increasingly complex patterns/shapes. CNN uses digital pattern recognition to determine the most important features of an image. It uses more layers to stack these patterns together, so very complex feature maps can be constructed.
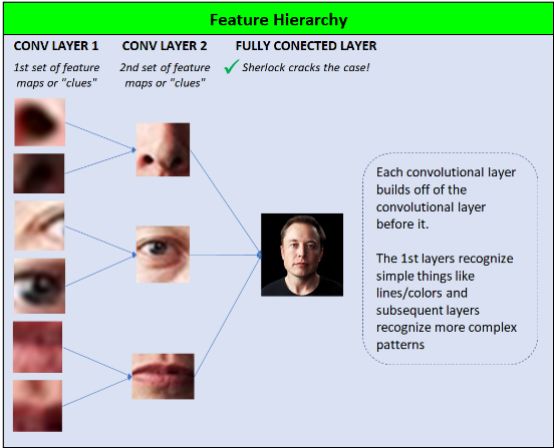
Convolutional neural network detection features
What is surprising is that CNN can learn these features by themselves, without the need for an engineer to write code to teach him what is 2 eyes, 1 nose, mouth, and so on.
In this way, engineers are more like architects. They told Sherlock, "I give you a stack ("convolutional layer") of 2 blank feature maps ("clues"). Your job is to analyze the image and find the most important clues. The first stack contains 16 feature maps. ("Clues"), the second stack contains 64 feature maps. Then you can use these detective skills to solve the problem!"
third step:

In order for Sherlock to find the "clue" in the case (ie "calculate a feature map"), he needs to use several tools, we will introduce them one by one:
Filter-Sherlock's magnifying glass
Convolution math-the weight of the filter x the pixels of the input image
Step size-move the filter on the input image
Fill-like "crime scene cordon" to protect clues
â–ŒSherlock's magnifying glass (filter)
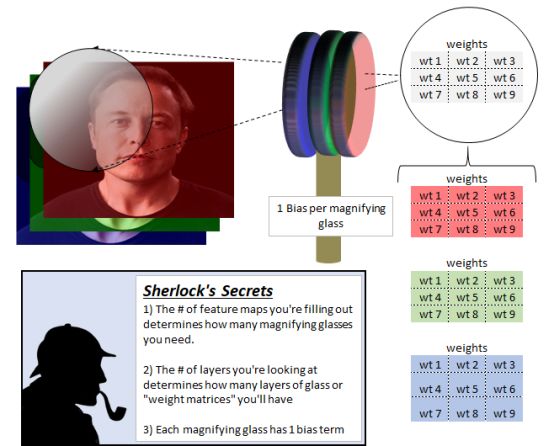
Sherlock is undoubtedly very keen and extremely insightful. But without his special magnifying glass or "filter", he would not be able to complete his work. So he uses different magnifying glasses to help him fill in the details of each blank feature map. So, if he has 16 feature maps, he will use 16 magnifying glasses.
Each magnifying glass is composed of multiple layers of glass, each of which has a different weight. The number of glass layers, our "filter depth", always matches the depth of the observed neural network layer.
In the beginning, Sherlock looked at the input image, it had 3 layers, red, green and blue. Therefore, our magnifying glass also has 3 layers. When we build a CNN, as the layer depth increases, our magnifying glass will also become thicker.
In order to build a feature map or "clue", Sherlock first takes out a magnifying glass and places it on the upper left part of the input image. The red glass layer can only see the red input image, the green glass sees the green image, and the blue glass sees the blue image.
The next step is to perform mathematical calculations.
â–ŒConvolution mathematics
Each pixel in our feature map is part of the clue. In order to calculate each pixel, Sherlock must use some basic multiplication and addition.
In the following example, we will use a 5x5x3 input image and a 3x3x3 filter, and each pixel requires 27 multiplications:
3 layers x 9 convolutions per layer = 27
Add 27 numbers together.
After adding the 27 calculation results together, we add another number—that is, the bias.
Convolution calculation-build a feature map
Let's zoom in and see. A pixel is made up of 27 multiplications. The picture below shows 9 of the 27 multiplications:
As far as the offset is concerned, you can think of it as the handle of each magnifying glass. Like the weight, it is another parameter of the model. Each training will adjust these parameters to improve the accuracy of the model and update the feature map.
Filter weights-In the above example, keeping the weights at 1 and 0 is to make the calculation more convenient; however, in a normal neural network, you can use a random lower value to initialize the weights, such as using (0.01) and ( 0.1) between the bell curve or normal distribution type method.

Element multiplication—used to calculate 1 clue
â–ŒStep length: move the magnifying glass
After calculating the first pixel in the feature map, how would Sherlock move his magnifying glass?
The answer is the step parameter. As the architect/engineer of the neural network, before Sherlock calculates the next pixel in the feature map, we must tell him how many pixels to move to the right. In practice, the step size of 2 or 3 is the most common. For the convenience of calculation, we set the step size to 1. This means Sherlock moves his magnifying glass 1 pixel to the right, and then performs the same convolution calculation as before.
When the magnifying glass reaches the far right of the input image, he will move the magnifying glass down 1 pixel and move to the far left.
â–ŒWhy does the step length exceed 1?
Advantages: By reducing the calculation and cache, the model training speed is faster.
Disadvantages: When the step size is greater than 1, you will lose the information of the picture due to skipping some pixels, and you may miss some learning modes.
But setting the stride to 2 or 3 is also reasonable, because the pixels next to each other usually have similar values, but if they are 2-3 pixels apart, it is more likely to be a more important pixel value change for the feature map/mode.
â–ŒHow to prevent the loss of information (loss of clues)
In order to crack this case, Sherlock needed a lot of clues at the beginning. In the above example, we used a 5x5x3 image, which is 75-bit pixel information (75 = 5 x 5 x 3). After the first convolutional layer, we only get a 3x3x2 image, which is 18-bit pixels (18 = 3 x 3 x 2). This means that we have lost some of the evidence, which will make his partner John Watson very angry.

In the first few layers of CNN, Sherlock will see many subtle patterns, which is a process of adding clues. In the later layers, the clues can be reduced by "downsampling", and Sherlock will pile up the subtle clues in order to see a clearer pattern.
â–ŒSo how do we prevent information loss?
1: Fill: We must “fill†around the image to protect the crime scene.

In our example, the filter needs to be moved 3 times before reaching the right edge, the same from top to bottom. This means that the output height/width we get is 3x3, so we lose 2 pixels when moving from left to right, and we lose another 2 pixels when moving from top to bottom.
In order to prevent this kind of information loss, the original image is usually filled with zeros (called "zero padding" or "same padding"), just like the cordon laid out at the crime scene, to ensure that no one tampered with the clues.
After filling, if Sherlock uses the same magnifying glass again, his 2 feature maps will be 5x5 instead of 3x3. This means that we will leave 50 pixels of information because the new output of this convolution is 5x5x2 = 50. 50 pixels is better than 18 pixels. However, we started with 75 pixels, so we still lost some clues.
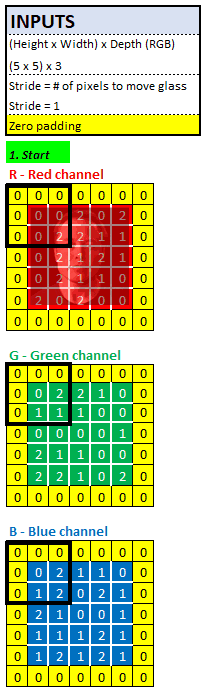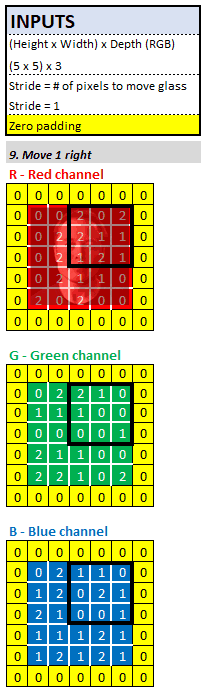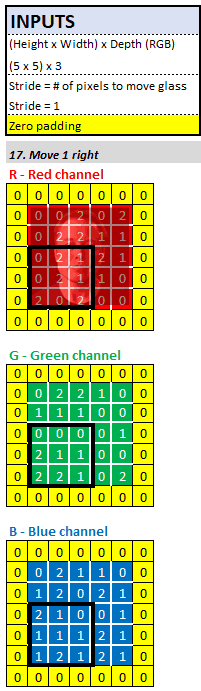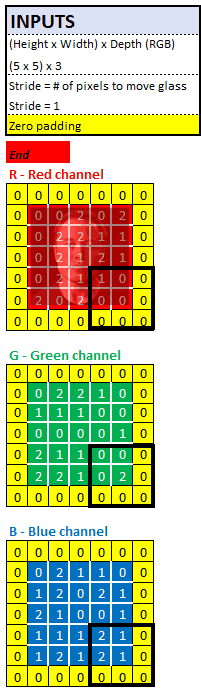
What else can we do?
2: Use more filters—provide more clues for Sherlock by adding at least 1 feature map to the convolutional layer
There is no limit to the number of feature maps or "cues" in our model, which is a controllable parameter.
If we increase the feature map from 2 to 3 (5x5x2 to 5x5x3), then the total output pixels (75) exactly match the input pixels (75), which can ensure that no information is lost. If we increase the feature map to 10, then there will be more information (250 pixels = 5 x 5 x 10) for Sherlock to filter to find clues.

In short, the total pixel information in the first few layers is usually higher than the input image because we want to provide Sherlock with as many clues/patterns as possible. In the last few layers of our network, the usual approach is to downsample to get a small number of features. Because these layers are used to identify more specific patterns in the image.
the fourth step

â–ŒReLU: Non-linear pattern recognition
It is very important to provide Sherlock with sufficient information, but now is the time for real detective work-non-linear pattern recognition! Like identifying auricles or nostrils, etc.
So far, Sherlock has done a lot of math to construct the feature map, but each calculation is linear (take the input pixels and perform the same multiplication/addition for each pixel), so he can only recognize the linearity of the pixels mode.
To introduce nonlinearity in CNN, we use an activation function called Relu. After calculating our feature map from the first convolution, the activation function checks each value to confirm the activation state. If the input value is negative, the output becomes zero. If the input is positive, the output value remains unchanged. The function of ReLU is similar to on/off. After the pixel value of each feature map passes through Relu, non-linear pattern recognition is obtained.
Going back to our original CNN example, we will apply ReLU immediately after convolution:
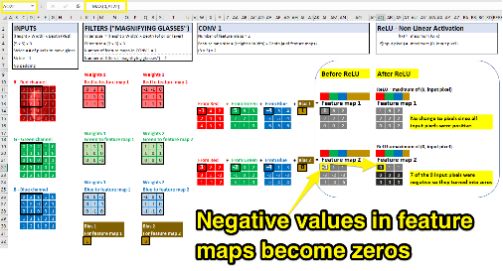
Although there are many nonlinear activation functions that can be used to introduce nonlinearity into neural networks (such as sigmoids, tanh, leakyReLU, etc.), ReLU is the most commonly used in CNN because they are computationally efficient and can speed up the training process.
the fifth step

â–ŒMax Pooling: Keep key few information in the brain
Now that Sherlock has some feature maps or "clues", how does he determine which information is irrelevant and which is important? The answer is maximum pooling!
Sherlock believes that the human brain is like a memory palace. Fools store all kinds of information, but in the end useful information is lost in chaos. Smart people only store the most important information, which can help them make decisions quickly. Sherlock's approach is Max Pooling, which allows him to keep only the most important information so that he can make quick decisions.

Max pooling is like Sherlock Holmes memory palace
With max pooling, he can look at the neighborhood of pixels and keep only the "maximum" value or "most important" evidence.
For example, if he is observing a 2x2 area (4 pixels), then only the pixels with the highest value will be kept and the other 3 will be discarded. This technique allows him to learn quickly and also helps to generalize clues that can be stored and memorized in future images.
Similar to the previous magnifying glass filter, we can also control the maximum pooling step size and pool size. In the following example, we assume that the step size is 1, and the maximum pooling is 2x2:
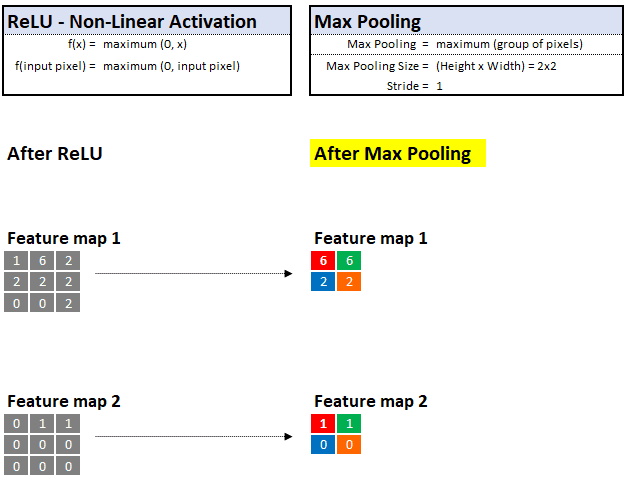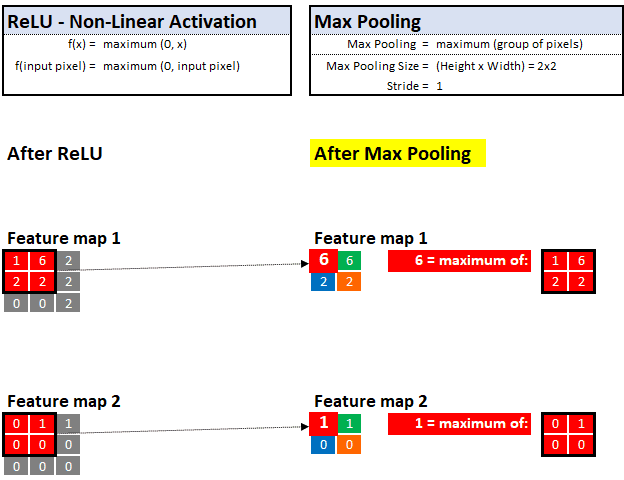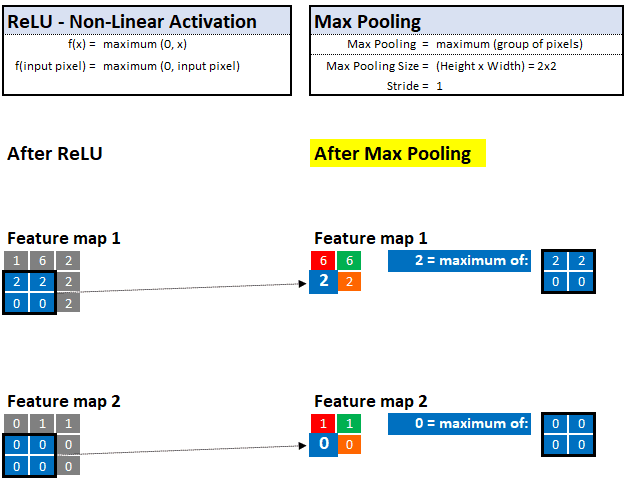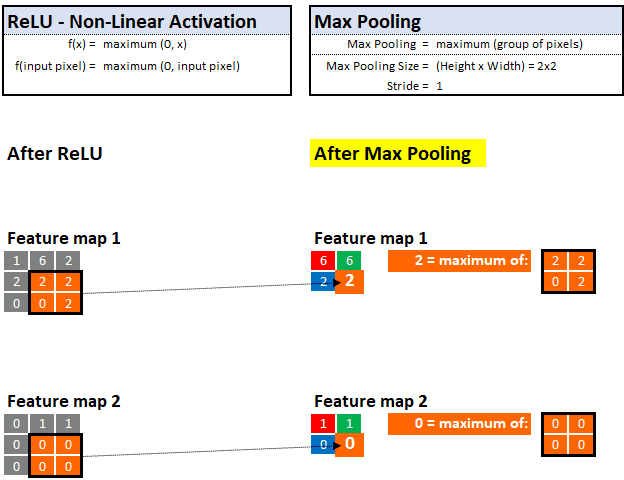
Maximum Pooling—Select the "maximum" value in the defined value neighborhood
After the maximum pooling is completed, we have completed the process of 1 round of convolution / ReLU / maximum pooling.
In a typical CNN, before entering the classifier, we generally have a few rounds of convolution/ReLU/pooling. In each round, we squeeze the height/width while increasing the depth, so that we don’t lose some evidence.
The previous steps 1-5 focused on collecting evidence, and then it’s time for Sherlock to check all the clues and solve the case:
Sixth step

When Sherlock's training cycle was over, he had a lot of scattered clues, and then he needed a way to see all of them at the same time. In fact, each clue corresponds to a simple two-dimensional matrix, but there are thousands of such clues stacked together.
Now all the clues he must obtain are collected and organized so that they can be shown to the jury in court.

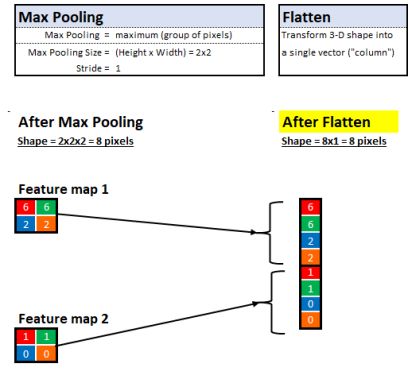
Feature map before flattening
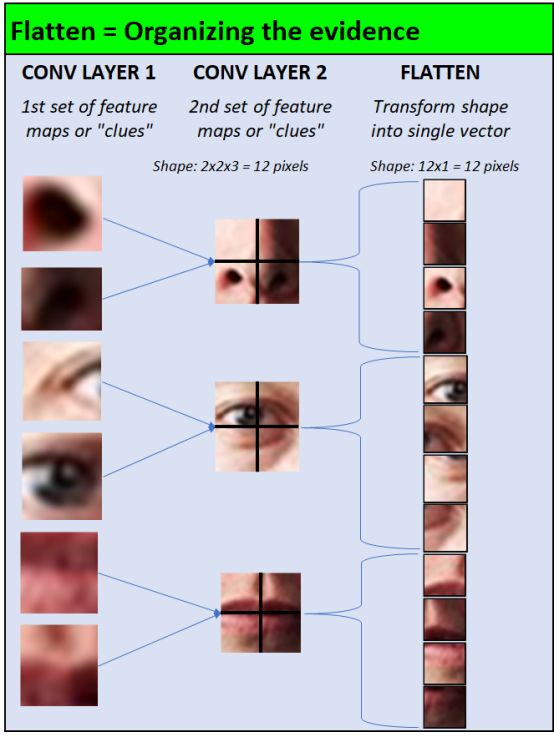
He used Flatten Layer to complete this work (Flatten Layer is often used in the transition from the convolutional layer to the fully connected layer). Simply put, the method of this technology is:
Each 2-dimensional pixel matrix becomes 1 column of pixels
Superimpose 2-dimensional matrices
The following figure shows an example of human eye recognition:
Back to our example, here is what the computer sees
Now that Sherlock has organized his evidence, he needs to convince the jury that his evidence ultimately points to the same suspect.
Seventh step

In the fully connected layer, we connect the evidence with each suspect. In other words, we are showing the link between the evidence and each suspect.
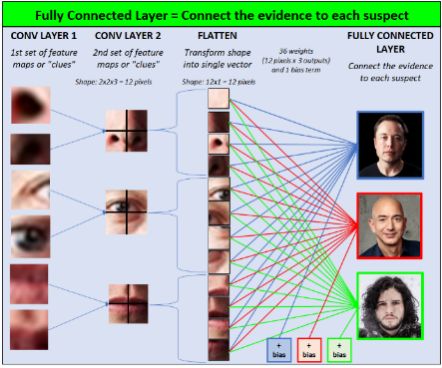
Fully connected layer—connects the evidence and each suspect
Here is what the computer sees:
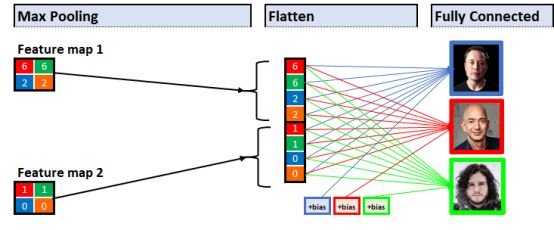
Fully connected layer
Between the Flatten Layer and each of the 3 output evidences are weights and biases. Like other weights in the network, when we first start training CNN, these weights will be initialized with random values, and over time, CNN will "learn" how to adjust these weights/bias to get more and more accurate predictions result.
It's time for Sherlock to crack the case!
Eighth step

In the image classifier stage of CNN, the prediction result of the model is the output with the highest score.
This scoring function has two parts:
Logit Score: raw score
Softmax: The probability of each output is between 0-1. The sum of all scores is equal to 1.
â–ŒPart 1: Logits-logical scores
The logit score of each output is a basic linear function:
Logit score = (evidence x weight) + deviation
Each piece of evidence is multiplied by the weight that connects the evidence to the output. All these multiplications are added together, and then a bias term is added at the end, and the highest score obtained is the model's guess.
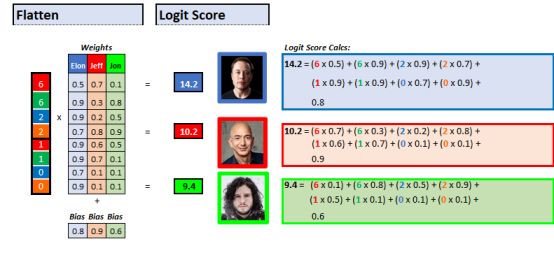
Logit score calculation
Why is the highest score not the final result? There are 2 intuitive reasons:
Sherlock's confidence level: We want to know how confident Sherlock is. When he is confident and the result is right, we can reward him; but when we believe that he is confident but the result is wrong, we have to punish him. When we calculate the loss ("Sherlock's accuracy") at the end, Sherlock will get the corresponding reward/penalty.
Sherlock's confidence-weighted probability: We hope to use a simple method to describe these results by a probability between 0 and 1, and get the same prediction score as the actual output (0 or 1). The correct matching image (Elon) is 1, and the other incorrect images (Jeff and Jon) are 0. The process of converting the correct output to 1 and the error output to 0 is called one-hot encoding.
Sherlock's goal is to get his prediction as close to 1 as possible to get the correct output.
â–ŒPart 2: Softmax-Sherlock's confidence weighted probability score
2.1. Sherlock's confidence level:
In order to find Sherlock's confidence level, we take the letter e (equal to 2.71828) as the base, and calculate the logit score for exponentiation. Make the high score higher and the low score lower.
It is also guaranteed that there are no negative scores in the exponentiation operation. Since the logit score is "possibly" negative, the following figure is the confidence curve:
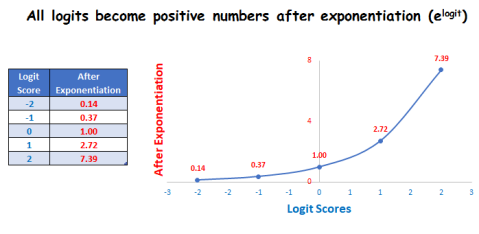
Confidence curve
2.2. Sherlock's confidence weighted probability:
In order to find the confidence weighted probability, we divide the confidence metric of each output by the sum of all confidence scores to get the probability of each output image, all of which add up to 1. An example with Excel is as follows:
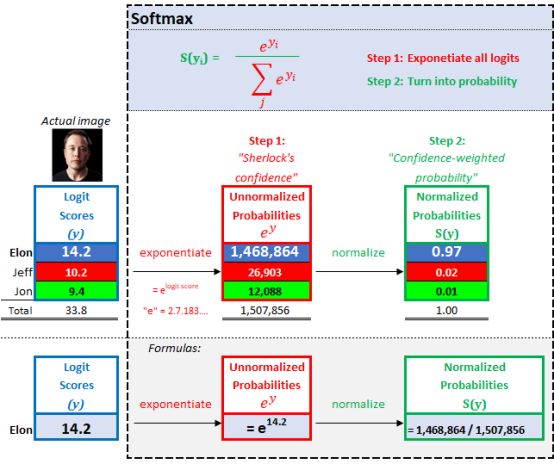
Softmax
This softmax classifier is very intuitive. Sherlock believes that the probability that the photo seen by the Terminator is Elon Musk is 97% (confidence weighted). The last step of our model is to calculate the loss. The loss value tells us how good (or bad) detective Sherlock is.
Step 9
Loss function

Every neural network has a loss function, and we compare the predicted result with the actual situation. When training CNN, as the network weight/bias is adjusted, our prediction results will be improved (Sherlock's detective skills become better).
The most commonly used loss function for CNN is the cross-entropy loss function. Searching for cross entropy on Google will show many explanations of Greek letters, which is easy to confuse. Although the descriptions are different, they are all the same in the context of machine learning, and we will cover the 3 most common ones below.
Compare the probability of the correct class (Elon, 1.00) with the probability that CNN predicts Elon (his softmax score, 0.97)
When CNN's prediction is close to 1, reward Sherlock
When CNN's prediction is close to 0, penalize Sherlock

The answers above are all the same! There are 3 different interpretations
â–ŒExplanation 1: A measure of the distance between actual probability and predicted probability
The intuition is that if our predicted probability is close to 1, our loss is close to 0. If our prediction is close to 0, we will be severely punished. The goal is to minimize the "distance" between the predicted result (Elon, 0.97) and the actual probability (1.00).
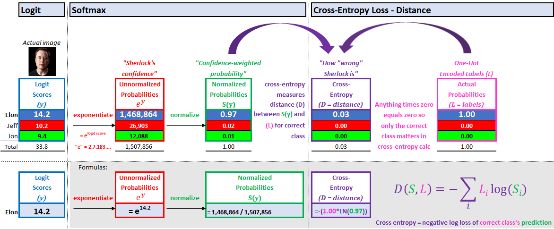
Cross entropy 1. Distance explanation
â–ŒExplanation 2: Maximize log-likelihood or minimize negative log-likelihood
In CNN, "log" actually means "natural logarithm (ln)", which is the inverse of the "exponent/confidence" done in step 1 of softmax.
Instead of subtracting the predicted probability (0.97) from the actual probability (1.00) to calculate the loss, we use log to calculate the loss. When Sherlook's predicted result is farther away from 1, the loss increases exponentially.

Cross entropy 2. Log loss interpretation
▌Explanation 3: KL divergence (Kullback–Leibler divergence)
KL divergence is used to measure the degree of difference between the predicted probability (softmax score) and the actual probability.
The formula is divided into two parts:
The number of uncertain actual probabilities. The amount of uncertainty in supervised learning is always zero. We are 100% sure that the training image is Elon Musk.
If we use predicted probability, how much "information" will be lost.
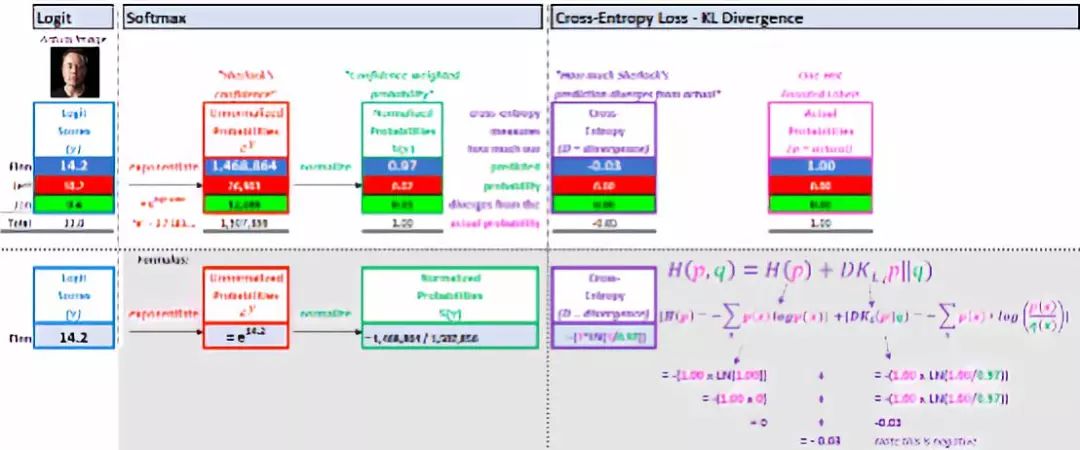
Cross entropy 3.KL divergence explanation
to sum up
With the help of Detective Sherlock Holmes, we gave the Terminator a pair of eyes, so he now has the ability to find and destroy Elon Musk, the protector of the free world. (Sorry Elon!)
Although we only train the Terminator to distinguish Elon, Jeff and Jon, Skynet has unlimited resources and training images. It can use the network we built to train the Terminator to recognize everything in the world!
Din Connector,Waterproof Cable Connector,Ip66 Wire Waterproof Connector,Waterproof Power Connector
Shenzhen Hongyian Electronics Co., Ltd. , https://www.hongyiancon.com