The big and small (big.LITTLE) chip design architecture is rapidly emerging. Under the power of ARM, the processor industry has begun to import a large number of big.LITTLE design architecture, which will allocate different computing tasks to the most appropriate core processing to achieve the best performance and energy saving effect, and help mobile devices. Manufacturers create more hygienic products.
The big.LITTLE chip design architecture will rise rapidly. ARM and the global IC design industry are actively collaborating to promote big.LITTLE technology. It is expected that there will be a large number of mobile processors based on this architecture in the second half of this year; it will be processed by assigning various computing tasks to the most appropriate core. Bringing the best performance and energy savings to help create the next generation of mobile devices.
In recent years, there has been a major change in the field of action. Smart phones have become the main tools for consumers to connect to the Internet. However, this involves a variety of high-performance computing tasks such as high-speed web browsing, navigation and games, as well as voice calls, social networks and electronics. The mail service is equivalent to a "continuous operation, always connected" background task with low demand.
At the same time, tablet devices are redefining computing platforms. These innovative design transformations are a new way for consumers to create interactions with content, bringing functionality that was originally limited to Tethered Devices into action areas to create real Smart new generation computing.
Taking into account the performance and power consumption of the big.LITTLE architecture
In response to the rapid changes in electronic devices, how will Moore's Law evolve? In the past, wafer performance was predicted to double every 18 months until the number of transistors increased from thousands to billions. However, if you look closely at a single processor, you will find that performance is almost stagnant because the system can consume The power has reached its peak.
For any processor in the future, the processing speed will be limited by the heat dissipation problem and will not be able to leap forward. Any device that reaches the Thermal Barrier will begin to melt. If it is a mobile phone, it will cause the device temperature to rise and cause user discomfort. In addition to the heat dissipation problem at the physical level, the energy efficiency will become quite poor. If the processor is tuned to speed up, the required energy consumption will increase exponentially, and in order to increase the efficiency of the last bit, follow-up The cost of thermal design is really high.
In the past, processor core area multiplication represented speed multiplication, but now area multiplication, speed only increases by a few percentage points, so complexity does not mean efficiency, which is one of the reasons for the limitations of a single core system. If it is not possible to speed up a single core speed, it is necessary to increase the number of independent cores. This also helps each core to cope with the task requirements it is assigned to. In view of this, Amgen International (ARM) proposed big.LITTLE in 2012. Processor architecture (Figure 1).
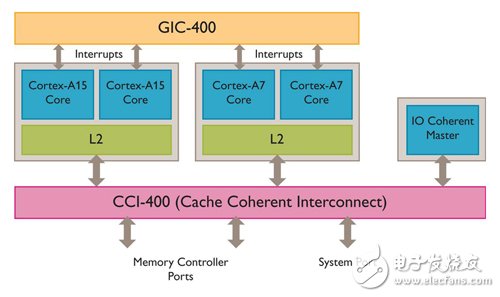
Figure 1 Big.LITTLE system structure diagram
The main purpose of big.LITTLE is to solve the biggest challenge in the IC design industry, which is to enhance the performance of the chip and extend the life of the device to extend the consumer's "continuous operation, always connected" action experience. The technology achieves this goal by combining a large high-performance processor core with a small (LITTLE) low-power processor core, and then selecting the appropriate processing in a seamless manner based on performance requirements. Device. More importantly, this action of dynamically allocating tasks has no effect on the execution of the upper application software or the intermediary software on the processor.
It has been applied to the big.LITTLE design of mobile devices on the market, combining the high-performance Cortex-A15 multi-processor cluster (Cluster) with the energy-saving Cortex-A7 multi-processor cluster. These processors are 100% compatible in architecture and support 40-bit physical address extension LPAE, virtualization extensions, and operational units such as NEON and VFP, which can be compiled for one of the processor types without additional adjustments. The software application runs smoothly on another processor.
Seamless switching of processor cores in response to mission requirements
The big.LITTLE system structure maintains cache Cache Coherency, whether it is cache memory in the same processor cluster or cache memory across different processor clusters. Take the consistency of the memory data. This cross-cluster consistency comes from the ARM CoreLink cache coherent sink architecture (CCI-400, which also provides I/O consistency for components such as the graphics processing unit (GPU) system such as the ARM Mali-T604).
Two clusters of central processing units can also transmit signals through a shared interrupt controller such as the CoreLink GIC-400. Among them, the system includes big.LITTLE switch and big.LITTLE MP (MulTIple-Processor) two execution modes. Since the same application can use Cortex-A7 or Cortex-A15 without adjustment, the application tasks can be randomly matched to On the right processor.
The switching mode is to enable different processor types to capture and reply to the software content when switching. In the case of CPU switching, each CPU in the cluster has a corresponding CPU in another cluster, and the software content is CPU-based, randomly switching between different clusters; if there is no running CPU in the cluster, Close the entire cluster and related L2 caches.
At the same time, this mode is also an extension of energy/performance management technologies such as Dynamic Voltage and Frequency Adjustment (DVFS). The switching action is similar to the conversion of the DVFS operating point. Since the operating point of the DVFS curve on the processor will change back and forth with different load changes, when the existing processor (or cluster) has reached the highest operating point, the software stack still needs to be more High performance, processor switching actions will occur, and another processor will perform the work. The operating point of this processor will also change back and forth as the load changes (Figure 2). When the performance requirements are no longer available, you can switch back to the previous processor (or cluster).
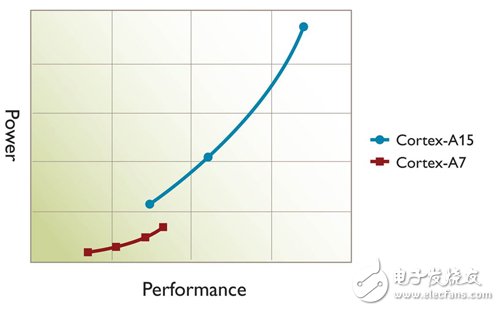
Figure 2 big.LITTLE switching mode DVFS graph
Obviously, consistency is the key to achieving the time required to speed up the switch, because it allows the state that has been stored in the Outbound Processor to snoop and reply on the Inbound Processor without having to Access to the main memory.
In addition, because the L2 of the processor has the function of cache consistency, when the task is switched, the data of the data can be snooped to improve the warm-up time of the incoming processor. At this time, the L2 cache memory is still The power state can be maintained; however, because the L2 cache from the processor cannot provide a cache configuration for new data, the power must be cleared and turned off to save power (Figure 3).
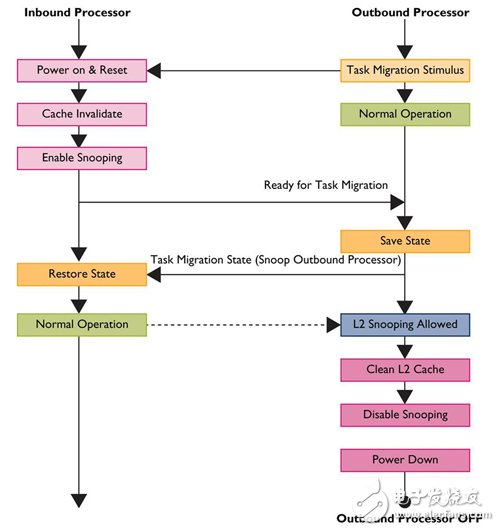
Figure 3 big.LITTLE operation task switching flowchart
Since the LITTLE processor clusters, each processor will correspond to a big cluster processor, so the CPU is in pairs (the Cortex-A15 and Cortex-A7 processors have CPU0, Cortex-A15 and Cortex-A7 processing). CPU1, and so on), whenever there is only one processor in each pair, the system will actively detect the load of each processor and move the content execution to the big core under high load. 4). When the load moves from the core to the core, it shuts down one of the cores. This mode allows the big and LITTLE core combinations to run at any time.

Figure 4 big.LITTLE switching mode DVFS graph
Outdoor Fibre Termination Box,Fiber Optic Distribution Cabinet,Wall Mount Fiber Distribution Box,Distribution Box Fiber Optic
Ningbo Fengwei Communication Technology Co., Ltd , https://www.fengweifiberoptic.com